
Domain Driven Design (DDD) in gewoon Nederlands
Introductie naar Domain Driven Design (DDD)
Als Lead Developer ben ik betrokken bij het opmaken van business cases, uitwerken van ideeën en het implementeren van softwareoplossingen. Een steeds vaker terugkomend thema is dat mijn relaties hun applicatie landschap willen moderniseren zonder opnieuw het wiel te willen uitvinden.Vaak wil men voortbouwen op het goede wat er al is. Meestal is het geen goed idee om de optie “opnieuw beginnen” ter tafel te brengen. Maar hoe kunnen we onze klanten dan wel op weg helpen?
Het opnieuw beginnen is dus geen optie. Werken met een “brown field” is dus het beginpunt. De aanpak waarmee ik start is het in kaart brengen van het probleemgebied. Hierbij wordt het bestaansrecht van de applicatie (het waarom en wat) onderzocht. Via dit model wordt vervolgens onderzocht hoe de applicatie opgeknipt kan worden op basis van thema’s in dit model. Dit ontvlechten van de applicatie wordt in software termen vaak het “ontvlechten van de monoliet” genoemd.In dit artikel, deel ik graag een methodiek die tegenwoordig heel actueel en toepasbaar is. Deze methodiek is Domain Driven Design (DDD).
Helaas is het zo dat bij het beschrijven van deze domain driven design methodiek (te) snel de route van abstractie en technologische gevolgen wordt bewandeld. Ik pak dat deze keer anders aan.

Zodra je googled op “DDD” of “domain driven design” krijg je een spervuur van termen, toepassingen en dergelijke tot je beschikking.
Hierboven een woordwolk van veel gebruikte termen.
Verschillende termen uit deze woordwolk zullen aandacht krijgen in dit en erop volgende artikel(en).Laten we beginnen bij het begin.
Het Swingtree project
Software ontwikkelen is een complexe inspanning die vaak leidt tot onbegrip. Dit onbegrip komt vooral voort uit het vertalen van de wens (het idee) naar de oplossing. Met alle goede bedoelingen en processen (“Scrum“, “Agile” !), blijkt jammer genoeg in de praktijk dat het resultaat lijkt op het beroemde “Swingtree project”.
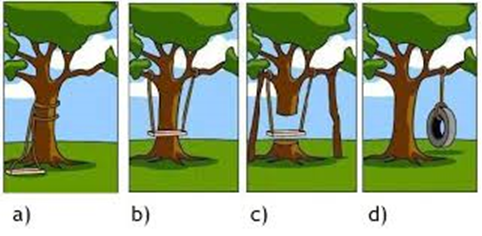
Het “Swingtree project” is een metafoor die regelmatig wordt getoond om aan te geven dat er wezenlijke verschillen bestaan in begrip:
- Wat de gebruiker / klant heeft gedeeld over de wens
- Wat de gebruiker / klant werkelijk nodig heeft
- Hoe de architect de wens heeft vertaald naar het ontwerp
- Hoe de ontwikkelaar het ontwerp heeft geïmplementeerd
Uiteindelijk blijft het ontwikkelen van software mensenwerk. Mensenwerk vereist veel investeren in communicatie en afstemming. Vooral in de fase van een project waar nog geen regel code is geschreven moet er veel worden gecommuniceerd en gedocumenteerd om zoveel mogelijk te voorkomen dat uiteindelijk een product wordt opgeleverd wat lijkt op de schommel. De methodiek Domain Driven Design is zeer bruikbaar zowel in de verkennende fase van een project, als in de realisatie.
Waarom kiezen voor domain driven design?
Onderaan de streep is het de bedoeling dat door middel van een gemeenschappelijke taal (“Ubiquitous language“) een ontwerp (“Domain Model”) ontstaat waarin middels afbakening van thema’s (“Bounded Context”) de onderwerpen (“Entities”) worden beschreven. Kernwaarde hierbij is dat dit wordt gedaan zonder verwijzing naar de oplossing zelf (technologie en software architectuur). Domain Driven Design (DDD) gaat dus over de wens / probleem en niet over de oplossing.
Ik beschreef net wat de “why” is van domain driven design. Dadelijk zal ik dieper ingaan over het “wat” van DDD. Het “wat” van domain driven design is het middel om tot het doel te komen. Dit middel is het komen tot een “domain model”.
Wat is een “problem domain”?
De term “probleemdomein” wordt vaak aangeduid in domain driven design voor het definieren van een functioneel gebied in een organisatie. Een applicatie zal nimmer alle processen ondersteunen van de organisatie. Denk bijvoorbeeld aan applicaties voor personeelszaken en inkoop. Organisaties van enige omvang hebben hiervoor altijd verschillende applicaties. Personeelszaken is bijvoorbeeld een “probleemdomein”.
Er wordt een “domain model” opgesteld. Wat is een “domain model”?
Een groot denker en pionier op het terrein van Domain Driven Design en DDD, Eric Evans zegt over het “model” het volgende: “every model represents some aspect of reality or an idea of interest. A model is a simplification. It is an interpretation of reality that abstracts the aspects relevant to solving a problem at hand and ignores extraneous detail in domain driven design”
Een architect en/of analist faciliteert het opstellen van het model. Wat heb je dan? Het model beschrijft het “uiterlijk” en “gedrag” van het gekozen probleem domein. Het “uiterlijk” is de verzameling van gegevens die van belang zijn. Hierbij is ook de relatie tussen deze gegevens interessant. Het “gedrag” beschrijft de processtappen en gebeurtenissen die met/op deze gegevens plaatsvinden. Je kan het ook menselijk maken. Het gedrag is wat van buitenaf wordt gezien. Dit gedrag heeft intentie/motivatie, dat zijn de gegevens. Binnen domain driven design wordt gedrag beschreven als een verzameling van “events” en de intentie als een verzameling van “entiteiten”. De verzameling van deze beschrijvingen worden geborgd in tekeningen en code.
Wat is het doel van het domain model?
In het begin van dit artikel wordt “swingtree project” beschreven. Het middel om dit soort projecten te voorkomen is het domain model. Dit is de “why” binnen DDD van het modelleren. Het model levert documentatie in de taal van de kenniswerker in het probleemdomein. Dit betekent dat het model in een taal is geschreven zonder technische oplossingen en begrijpbaar voor de kenniswerker en andere betrokkenen. Concreet, er moeten termen worden gebruikt van de “werkvloer”. Als meerdere termen voor hetzelfde onderwerp worden gebruikt, moet de best passende term worden gekozen.
Het primaire doel van het model is dus het beschrijven van de “why” en “what” van het probleemdomein.
Door middel van het model wordt:
- Kennis over het probleemdomein geborgd
- Spreken toekomstige gebruikers en de ontwikkelaars dezelfde taal
- De oplossing in code herkenbaar, ook in de toekomst
Een secundaire doelstelling is het hebben van een basis voor het software ontwikkelteam om de oplossing te realiseren van het probleemdomein. Deze basis moet in de code worden herkend zodat ontwikkelaars snel vanuit het probleemdomein, de technische oplossing eigen kunnen maken. Op deze manier wordt code herkenbaar en wordt alleen noodzakelijke code geschreven. Binnen DDD wordt de taal van de werkvloer “ubiquitous language” genoemd.
Een gestructureerde aanpak
Zonder het gestructureerd aanpakken van de analyse om tot het model te komen, kan een applicatie ontstaan zoals hieronder weergegeven. Voor een klein probleemdomein hoeft dat geen probleem te zijn. Echter, het probleem domein zal altijd onderhevig zijn aan veranderingen en wellicht uitbreidingen. Het resultaat is een nog complexer plaatje. Binnen DDD worden dergelijke oplossingen “Big ball of mud” genoemd.
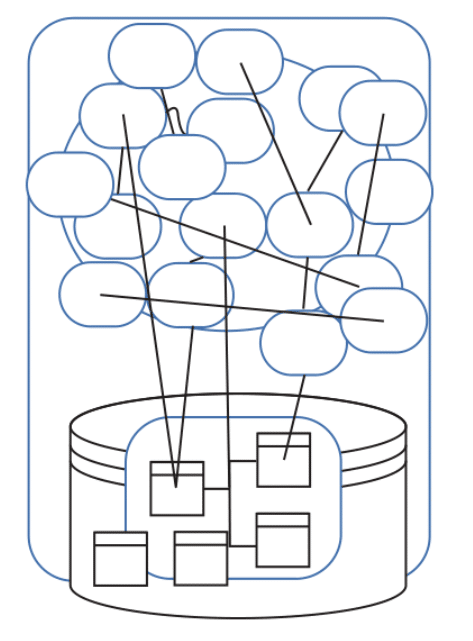
Bron: Patterns, Principles and Practices of Domain Driven Design DDD by: Millet & Tune
Beter is om deelgebieden van het probleemdomein te beschrijven. Dit zijn de “subdomains” van het probleemdomein. Per subdomein worden vervolgens de modellen opgesteld. Dit betekent ook dat de oplossing (de architectuur) bestaat uit subdomeinen. Het realiseren van de oplossing gebeurt met focus en kan zelfs door verschillende teams worden uitgevoerd. De applicatie resulteert dan in een plaatje wat vergelijkbaar is met de onderstaande.
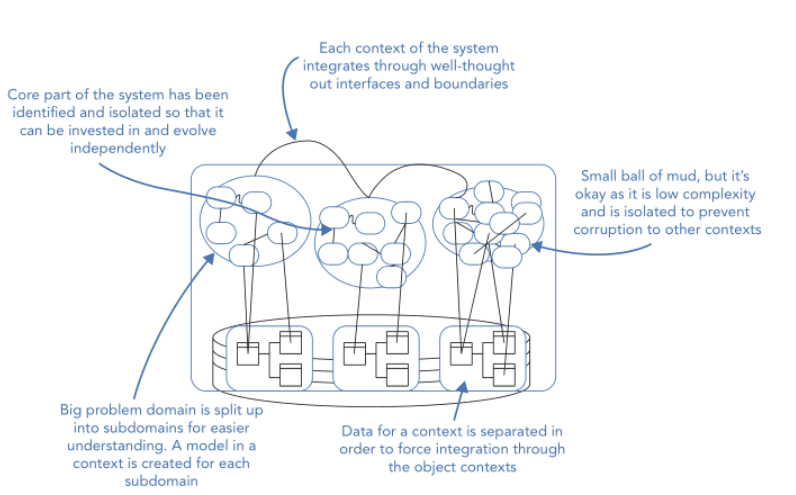
Bron: Patterns, Principles and Practices of Domain Driven Design by: Millet & Tune
Aggregates, entiteiten en value objecten
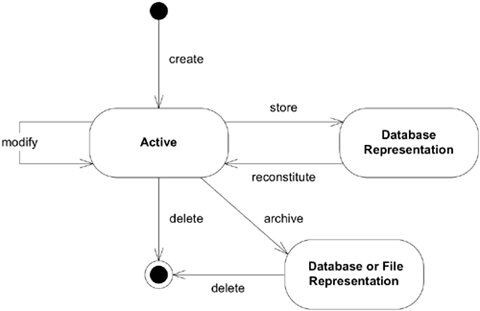
Om het begrip rond aggregates, entiteiten en value objecten goed te begrijpen is begrip nodig van de zogenaamde “life cycle” van objecten in het algemeen. Domain driven design is een manier die de status beschrijft van een object zijnde: “actief”, “verwijderd” of “gearchiveerd”.
Een “actief” object is in het geheugen geladen (bijvoorbeeld uit een database) en wordt actief mee gewerkt of gebruikt om entiteiten binnen een bounded context te benaderen.
Een “verwijderd” object krijgt deze status eigenlijk middels een “onzichtbaar” vlag omdat entiteiten eigenlijk nooit verwijderd worden (is overigens een uitdaging in het perspectief van GDPR en “mij vergeten”).
Een “gearchiveerd” object is opgeslagen en niet geladen in het geheugen van de applicatie.
Bovenstaande is door Eric Evans grafisch weergegeven in zijn boek “Domain Driven Design (DDD), tackling the complexity in the heart of software“.
Moderne software oplossingen bevatten snel diepgaande structuur van objecten middels verschillende lagen. In aanvulling hierop worden software oplossingen steeds meer gebruikt via verschillende apparaten en kunnen deze draaien op verschillende besturingssystemen. Veel gebruikers muteren gegevens tegelijkertijd hierdoor. De uitdaging is daarom om de waarheid van de objecten te garanderen. Deze consistentie van veranderingen “eventual consistency” is DE uitdaging van DDD gedreven oplossingen.
Consistentie wordt bepaald via een verzameling van regels, in DDD termen “invariants” genoemd. Deze “invariants” moeten op 1 plek worden vastgelegd. Zij bepalen de samenhang van de objecten in de bounded context en zorgen ervoor dat 1 waarheid blijft bestaan. Die ene plek is het hoofd object in de bounded context. Dit hoofd object wordt de aggregate root genoemd. Doordat dit type object verantwoordelijk is om de “invariants” te bewaken, moet het de rol spelen van de “poortwachter” voor de bounded context.
In andere woorden, alleen via de aggregate root kan de bounded context en haar inhoud worden aangesproken en worden gewijzigd.
Aggregates en hun bounded contexts
De volgende regels worden in acht genomen voor aggregates en hun bounded contexts:
- De aggregate zorgt voor consistentie binnen de bounded context. Dit betekent dat het verwerken van gerelateerde objecten binnen 1 transactie moet plaatsvinden
- De aggregate objecten hebben een identiteit die over alle bounded contexten geldt. Op deze manier zijn uitwisselingen mogelijk van gegevens tussen de bounded contexten. Overige entiteiten binnen een bounded context, hebben een lokale identiteit. Er bestaat geen garantie dat voor entiteiten met dezelfde naam en identiteit maar in verschillende bounded contexten, zij ook identiek zijn. Immers, bijvoorbeeld de entiteit “Person” kan in de bounded context van Employee totaal iets anders voorstellen als in de bounded context Sales
- De opbouw van de structuur van objecten uit een opslag, gebeurt altijd via de aggregate. De aggregate heeft kennis van de interne structuur in de bounded context
- Een aggregate kan referenties hebben naar andere aggregates in andere bounded contexten
- Zodra er wijzigingen worden aangebracht via de aggregate, moeten deze onmiddelijk worden verwerkt in de opslag en moeten alle regels voor consistentie zijn nageleefd
Wat zijn Aggregates en value objects?
Aggregates is dus een speciaal object in domain driven design. Conform de “ubiquitous language” is de aggregate dus een entiteit met speciale eigenschappen en gedrag. Andere objecten binnen de bounded context zijn dus of reguliere entieiten of value objects.
Value objects, weer een abstracte term die toelichting vereist. Het verschil tussen een entiteit en een value object is dat de laatste geen unieke identiteit heeft. Ook is een value object onwijzigbaar. Waarom zou je dergelijke objecten gebruiken en hoe pas je deze toe? Een voorbeeld wordt gebruikt om deze vragen te beantwoorden.
Neem de bounded context van OrderManagement (fictief voorbeeld). Binnen deze bounded context is de Order de aggregate en deze heeft een collectie van OrderLine objecten. Het OrderLine object heeft informatie nodig over het Product. Product wordt in dit voorbeeld beschreven door een naam en SKU code. Stel nu dat deze eigenschappen als eenvoudige eigenschappen in de OrderLine worden ondergebracht. Niets weerhoud een onwetende ontwikkelaar ervan de productnaam aan te passen van de Orderline. Echter, dit is niet toegestaan omdat men zich kan voorstellen dat de naam en SKU code bij elkaar horen.
Om dit te voorkomen wordt Product gebruikt als value object. Indien het bestaande Product op de OrderLine aangepast dient te worden, dan passen we niet de eigenschappen van Product aan, maar vervangen we de huidige instantie van Product door een nieuwe instantie van Product.
Wil je meer weten over DDD en domain driven design of wil je weten op welke manier je domain driven design kunt toepassen in je eigen organisatie?
Neem dan contact met me op, ik help je graag.
Auteur: Arjen Kraak, Bergler Competence Center © 2021



{kind=link}
{kind=link}
{kind=link}
{kind=link}